Let’s start with a diagram, that outlines what we’ll describe right below. It’s best if you keep it open on the side, while reading the rest of the description.

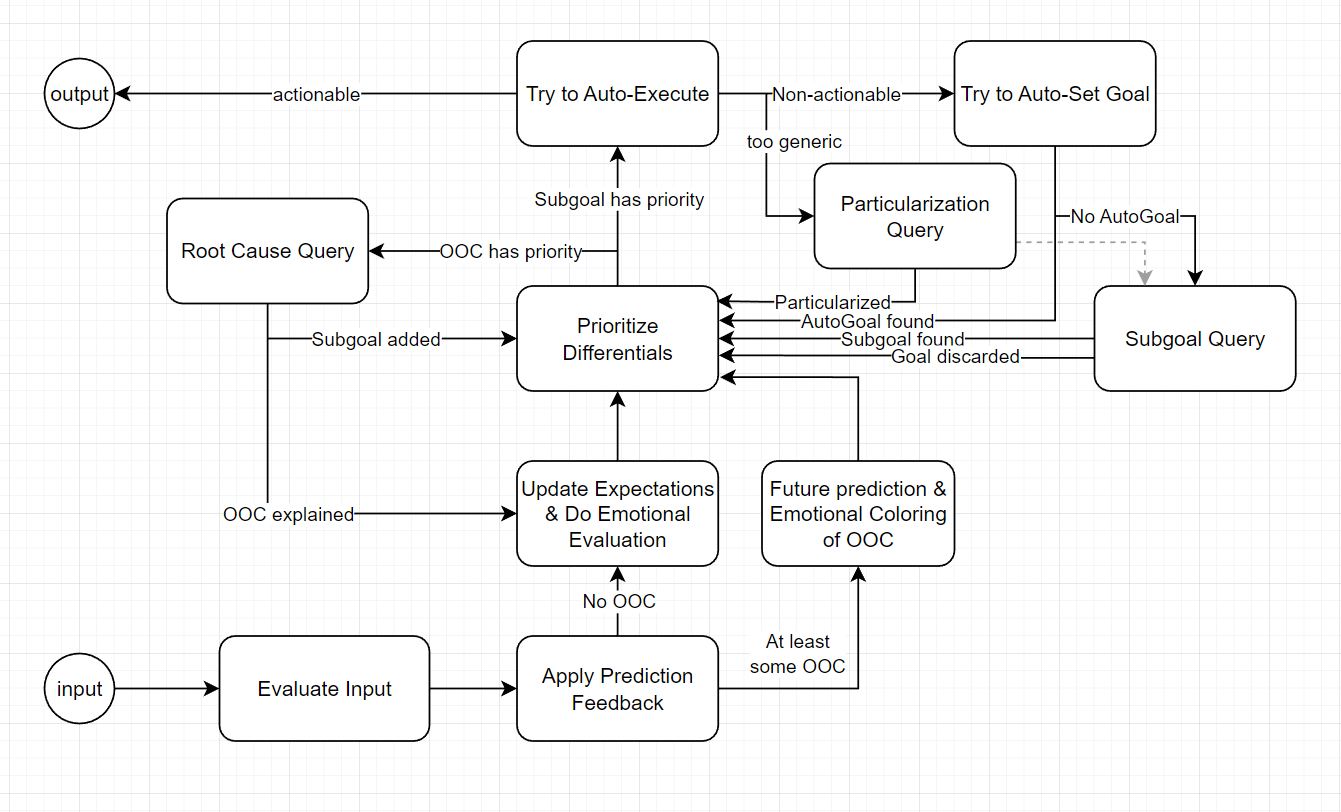{kind=link}
A. We maintain an internal state and predict the future
- Future prediction is at the heart of this algorithm. To predict the future, we need a starting point and a prediction.
- As a starting point, we maintain a set of currently active assumptions about the world (the “Internal state“).
- We have also built over time a library of “if this then that” predictions, i.e. if this Internal State, then this outcome.
- The combination of those two allow us to use past experiences to form expectations about future outcomes.
B. We learn from reality to improve our predictions
- We constantly compare actual outcomes (from our senses) vs predicted outcomes.
- Predicted outcomes that materialized (let’s call them “in-context”) are an opportunity to reinforce this prediction in the library and add this outcome in the Internal State.
- Predicted outcomes that failed to materialize are an opportunity to penalize this prediction in the library.
- Outcomes that weren’t predicted are an opportunity to add a new prediction in the library, so that we predict it next time. We also update the Internal State to reflect the new reality.
- Let’s name prediction failures “Out-of-context (OOC)“. We’ll elaborate more on that later.
C. We remember which outcomes led to positive/negative emotions
- When we experience something pleasurable or painful, the outcomes that were part of our Internal State get “emotionally colored”. Pain/pleasure that is stronger or lasts more or is repeated, builds up more coloring in that outcome. But emotional coloring also fades over time, if not reinforced with new, similar experiences.
D. We use our predictions to infer future pleasure/pain we might experience
- Predictions of emotionally colored outcomes generate motivation for us to act, i.e. to minimize discomfort and/or maximize pleasure. Let’s call those “Driving Pockets” (DPs). The size of the DP depends on how much emotional coloring has been stored on that outcome and how strongly it’s being predicted. Of course, the strongest possible prediction is if this outcome is part of what we assume as reality, i.e. if we’ve integrated it in our Internal State.
E. We sponsor outcomes that will help us maximize pleasure & minimize discomfort
- Initially, either through chance or via external help (e.g. parents), we experience outcomes that eliminate pain or deliver the pleasure. This is an opportunity for us to store “if this then that” associations of which outcomes deactivate which Driving Pocket.
- Therefore the next time such a Driving Pocket occurs, we know what outcome we want to sponsor! We issue a Request to activate this outcome. The size of the DPs dictates the amount of attention we’re willing to invest to make it happen.
F. Requests that can be immediately actioned, get executed on-the-spot
- By moving our actuators (muscles) we learn what outcome they can produce in different Internal States.
- Due to this, we have gradually augmented our “if this then that” library with single-action routines: “if I’m in this Internal State and I activate these muscles, I will get that”.
- Therefore, we can solve it backwards: If I want “that” to happen, and I’m in this “Internal State”, what do I need to activate?
- Any Request outcome for which we have an actionable solution stored in our library gets activated on-the-spot, without the need to focus our attention on it.
G. We assume all actions will succeed, and refocus our attention only if they fail
- Since we found that action from its expected outcome, we go ahead and predict/expect this outcome. At the same time, we activate a “Promise” on it, which temporarily deactivates the Request.
- Since actions have a lag until they affect the environment and generate new external input for us, we can go ahead and focus on other things (multi-task), being optimistic that it’ll work out as predicted.
- If external stimuli come that are contradictory to our expectation, it will generate Out-Of-Context and prompt us to deal with it. Similarly, if no stimuli come that match our Request, then the Promise will expire and the Request will be pending again, forcing us to refocus our attention.
- So it’s ok to be optimistic and multitask to something else, because we have the mechanisms in place to go back to it, if necessary.
H. Requests can act as Subgoals, to trigger multiple concurrent actions
- For a child to throw a ball, it needs to concurrently extend its hand and let go of the ball. Those are two different single-action goals that need to be triggered close together.
- Through trial & error, we learn to combine multiple single-action goals together, building a hierarchy of goals & subgoals (& subgoals…). The high level Request of “throw ball” unlocked two lower level Requests of “extend hand” and “release grip”, which were single-action outcomes and therefore get actioned.
I. We chain single-step action hierarchies into multi-step choreographies
- The single-step action combo alters our environment and therefore our internal state. The new internal state can wake up new “if this then that” Requests, which will trigger new action combos.
- In this way, we gradually add length to our choreographies, making them multi-step. Multi-step choreographies work in the same way as single-step, with a Promise for the Requested outcome issued/renewed with every step, and then ultimately delivered through actions that alter our environment. Thus, the brain doesn’t care if it’s single-step or multi-step, as long as the action outcomes are expected and the Promises get matched with the new reality at every step.
- In the same manner, we can add breadth (variability). If our action can have multiple outcomes (e.g. a tennis ball might bounce unpredictably due to its spin), over time we can build a routine (a series of actions) that reacts to this outcome as well. So regardless of what branch reality follows, we have an action routine readily available for execution.
J. We can merge all attention seeking mechanisms into 1: “Differentials”
- Returning to the topic of Driving Pockets, Requests & Out-Of-Context:
- A strong prediction of a future with a strong emotional coloring (good/bad – what I call Driving Pocket) that I don’t have a way to achieve/avoid, is a reason for turning my attention to solve this issue.
- Similarly, a strongly predicted outcome that didn’t become a reality soon after is reason for concern. It means that our future prediction mechanism is flawed and should be fixed, because it’s the basis for identifying opportunities for pleasure and avoiding risks of discomfort (i.e. for deactivating Driving Pockets).
- A strongly requested outcome that didn’t become a reality soon after (i.e. an expired Promise), is also reason for concern. It means that we failed to capitalize on a potential pleasure or we failed to mitigate a risk of discomfort.
- All of these failures are important and we can group them under one mechanism, called “Differentials”. These represent predictions or desired outcomes that we could not materialize.
- So a Differential is about either something Unexpected or Unattained.
K. We can only notice what is Unexpected or Unattained
- We already said that Expectations are compared against the inputs we receive from our environment and everything that was expected gets filtered out; it does not get served to our conscious mind!
- Our conscious mind receives info on a need-to-know basis. We only notice & deal with Differentials, because the main job of our conscious self is to eliminate Differentials!
L. We solve Differentials by investing extra “battery” to specific brain circuits
- We have a Differential because the existing brain circuits, powered by a steady supply of current, was not enough to predict or deliver this outcome.
- Therefore to find a solution we need to invest extra “battery” power to run a graph search algorithm and hopefully identify a solution.
- Let’s discuss how this graph search algorithm could work:
M. Root Cause query: We solve Unexpected by discovering a chain of missing assumptions that should get integrated in our internal state
- Unexpected (or Out-Of-Context as we named it earlier) means we didn’t have a prediction in our library that linked our current internal state with this outcome.
- If we consider our current prediction perimeter (that starts from Internal State) a “one-hop prediction”, then there are 3 possible ways to solve the Unexpected:
- a) Either this prediction is 2+ hops away
- which means we need to add nodes/assumptions to our Internal State
- b) Or this prediction is 1 hop away, but only if a currently active assumption of our Internal State wasn’t active
- which means we need to evaluate whether to deactivate it
- c) Or this prediction is totally new to us
- which means we need to integrate it as a new one-hop prediction for this internal state
- a) Either this prediction is 2+ hops away
- In all 3 cases we invest “battery” and do our graph search starting from the end and going backwards.
- if it’s (a), then we’ll search & gather one or more interim nodes (assumptions) and hopefully manage to trace our path back to the currently active internal state. And then we need to evaluate whether it’s ok to update our current internal state with those extra assumptions (we’ll discuss how in section P), so that it becomes a one-hop prediction. Those extra assumptions are the “Root Cause” for why our prediction initially failed.
- If it’s (b), then in our search we’ll find an internal state that is very similar to our currently active internal state, with a few differences. And then we need to evaluate whether it’s ok to deactivate those assumptions (we’ll discuss how in section P), so that it becomes a one-hop prediction. Those no-longer-active assumptions are the “Root Cause” for why our prediction initially failed.
- We ultimately reach (c) if both (a) and (b) failed. We searched but couldn’t find an explanation from our existing knowledgebase, so we need to accept one more rule “if this then that”. We tentatively store it in our database and if it happens many more times, it will be reinforced and thus become a solid prediction for us.
N. Subgoal query: We solve Unattained by discovering a chain of outcomes that need to be Requested to achieve the overall goal
- Unattained means we didn’t have an actionable routine ready to execute and make the Request a reality (and thus deactivate it in-time). Let’s name all prebuilt choreographies (regardless of whether they’re single-step or multi-step), as “one-hop actions”. So if it’s difficult, it means that none of our available one-hop actions can Promise the Requested outcome.
- Therefore we need to invest “battery” and do a graph search for multi-hop options. Again, we start from the end and go backwards:
- a) Maybe we have a one-hop action choreography that can achieve the Unattained, but it only gets triggered when in a different Internal State (e.g. if we have a specific tool at hand, or if we’re in a specific location). Then, let’s do a recursion and consider this non-active Internal State as the Unattained, and try to solve it in the same manner. Can we achieve this targeted interim Internal State via a one-hop action from our current Internal State?
- Eventually, we can build backwards a chain of interim goals/outcomes until we reach something that is one-hop actionable from our current Internal State.
- b) Maybe the Requested outcome is achievable via a one-hop action, but that action is one-hop only if something in our internal state was not active (e.g. I could get my peace & quiet if I was not in the room with the noise). Thus, we can evaluate whether we should Request the deactivation of the currently active Internal State node, and do a recursion, trying to find one-hop actions that can deliver this.
c) If both of the above fail, unfortunately there’s no easy solution that is equivalent to (c) of the Root Cause analysis. Instead, we either rely on chance or the help of our environment (e.g. parents) to bring the solution closer to us, to make it one-hop actionable.- Another thing that helps us in such situations is that: the longer we leave it unsolved, the bigger the Driving Pocket becomes (e.g. because we become hungrier) and thus we’re willing to invest more Battery for the search and even try out more desperate alternatives, that are matching less to our current internal state, but are at least remotely relevant and thus might work (because if you’re dying of hunger, “might work” is good enough).
- a) Maybe we have a one-hop action choreography that can achieve the Unattained, but it only gets triggered when in a different Internal State (e.g. if we have a specific tool at hand, or if we’re in a specific location). Then, let’s do a recursion and consider this non-active Internal State as the Unattained, and try to solve it in the same manner. Can we achieve this targeted interim Internal State via a one-hop action from our current Internal State?
O. We maintain a sponsorship chain to keep track in our graph search
- In the graph search algorithms, we have two stable points (the Differential & the Internal State) and millions of different paths in-between, that may or may not be able to bridge the two. It’s easy to get lost. To avoid losing track, and to be able to easily backtrack in our search, we maintain a chain of sponsorship.
- Starting from the distant node, the Differential, it sponsors a subgoal, that subgoal sponsors a subgoal, and so on, until we reach back the Internal State. Of course, every hop is tied to a probability less than 100% (which represents our confidence on whether the action would deliver the outcome), therefore sponsorship decays as we build long chains of hypotheticals. Therefore it’s entirely possible, that if we don’t manage to ground it to reality (our current Internal State) within a few hops, we run out of battery and thus need to backtrack and try another path that is hopefully shorter or built via stronger links.
- Of course, if the original Differential dissipates for any reason (the danger cleared, or our emotions dissipated or our parents solved the problem for us) the top of the chain loses sponsorship and thus the whole search stops.
P. We know our graph search is working when interim solutions are reducing total Differential
- Every interim solution that we try to activate gets tentatively integrated in the Internal State and contributes to a new set of future predictions. And as with every prediction, this tentative future will also be emotionally evaluated. This helps us assess whether this tentative solution can help predict the Unexpected or achieve the Unattained.
- Here are some possible outcomes:
- Ideally this solution totally eliminates/predicts the current Differential. Or at least it can greatly reduce it.
- But it might have unwanted side-effects, meaning it also expects other things that are quite different from what is already active in the Internal State, i.e. it would generate new Unexpected nodes.
- Similarly, it might predict outcomes that have negative emotional coloring, meaning this solution would trigger new Driving Pockets (Differentials) if we decided to make it a reality.
- As you understand, a candidate solution might reduce total Differential, but it might also increase total Differential! Therefore a stable interim step is one that we predict will significantly reduce the total Differential.
- Keep in mind that if the interim step (subgoal/assumption) is not one-step away from our Internal State, then it’s also a Differential by itself! Therefore we might have cases where this interim assumption can totally explain the Unexpected, but then we need to start the process all over again and explain the interim assumption! Which is fine, as long as the total Differential is decreasing with every step (because it brings us closer to our one-hop prediction/action perimeter).
Q. All connections & activations decay over time, if not reinforced (use it or lose it)
- Internal State active nodes become inactive over time if they don’t contribute to the prediction of latest events.
- Driving Pockets become less active over time if a visceral need (like hunger signals from stomach) doesn’t continually reinforce them.
- Emotional coloring stored in nodes becomes less strong over time (so we won’t associate a face/place/word/etc. with a negative experience as strongly over time), unless reinforced.
- Promises die out quickly, unless reinforced by the next step in the choreography or validated by external stimuli that matched the promise.
- “If this then that” future predictions lose their strength if they’re not reinforced or similar circumstances don’t reoccur in the future.
- Our “library” of one-step actions also decays over time, if not repeatedly used.
And of course, if they get used and prove non-useful, they get a temporary penalty (so that the graph search algorithm can pick a different alternative next) and might even be permanently penalized, to make them less likely to be picked next time in similar circumstances.
R. Particularization query: We abstract away similar solutions and that’s why we sometimes need to particularize goals first, to make them actionable
- No two situations are exactly alike, but we can’t always be storing an ever-growing library of slightly different solutions for slightly different Internal States. It’s in our best interest to compress & group them up into a more abstract/generic goal that holds the common denominator of these detailed solutions.
- This means that sometimes the Auto-Goal query will be returning a generic goal that is not actionable because it first needs to be particularized to the specific case in front of us. Essentially this means that we need to activate some extra nodes in our Internal State that will disambiguate which of the “children” of this parent solution should be picked.
- To particularize a goal, we need to activate some patterns on our Internal State that are the missing prerequisites of any of the children of this parent goal. We can pull these from memory (recent memory or long-term memory). Or if that fails, we can even set a subgoal to initiate actions, that will help us activate those patterns.
- E.g. when you need to remember the name of the song to answer your friend’s question, you have a high-level goal already active, but the specific solution that will deliver pleasure to you is still unreachable, until a specific type of pattern (the song name) gets activated in your internal state. If your memory fails to bring it back, you might activate a subgoal that is actionable, e.g. to open Spotify on your mobile to search for it.
- There are cases where this particularization query can’t get enough battery to complete the task, because a bigger differential might have captured our attention. In those cases, it’s possible that we’ll do fuzzy routing and just forward to action the strongest of the children of the parent/generic solution, being optimistic that this would be enough to continue the execution of the choreography. Because it it goes really bad, the size of the Differential will increase anyway and thus enable us to switch our attention back to this and dedicate more battery to it.
Next up, let’s see a hypothetical example, to see how all these play out in real time. (coming soon)